Why TeraScience
We address the reproducibility problem.
The Reproducibility Problem
Science is about generating data and algorithms and reusing them.
Science is about generating data and algorithms and includes research done in academia or industry. Although driven by different interests, both require substantial investments in time and money for data collection and the development of algorithms, which are not utilized to their full potential if the research output is not reproducible. Reproducibility in academia can accelerate scientific progress. In industry, it develops an edge for a company over its competitors by cutting costs and becoming increasingly sophisticated in its analytics delivery.

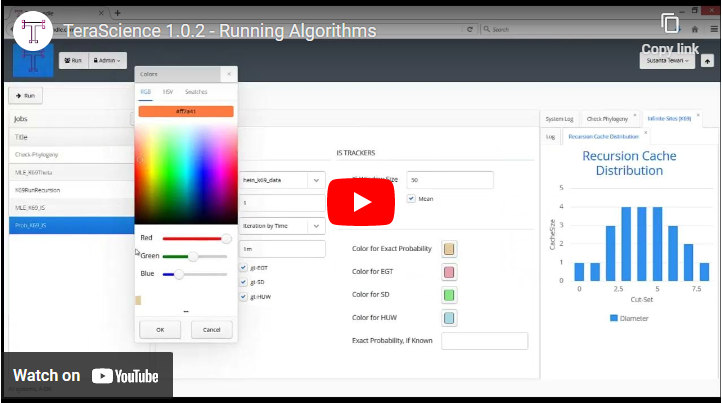
Approach of TeraScience
Reproducibility via Re-usability
TeraBundle approaches reproducibility via re-usability and thus fully recovers the research investments with compounding interest. We carefully engineer data and code that continues to pay dividends for years. Individual researchers, labs or companies have little incentive to dedicate the time skills necessary to practice reproducible research. Reproducibility is the ultimate standard of scientific progress in academia. The one-to-many relationship between problems and solutions can give a significant edge for companies over their global competitors.
TeraScience Platform
Analytics driven by API and Generics.
We model data after its associated processes with its sources and formats well encapsulated as plug-ins. Data and algorithms have clean API based on software engineering principles. Extensive framework for writing small, well-defined generic analysis with multiple extensible output processors as plug-ins.Output processors can provide feedback both during job execution and at the end.
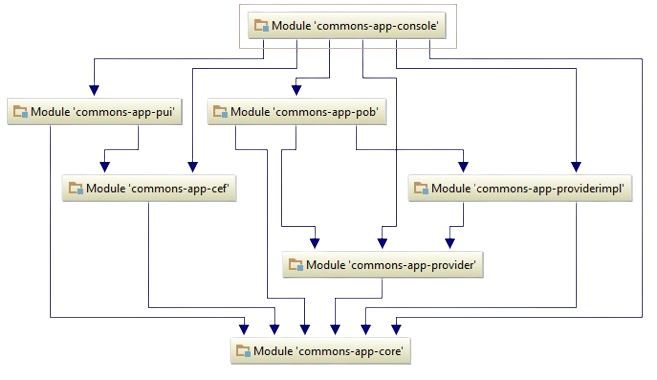
Research Marketplace
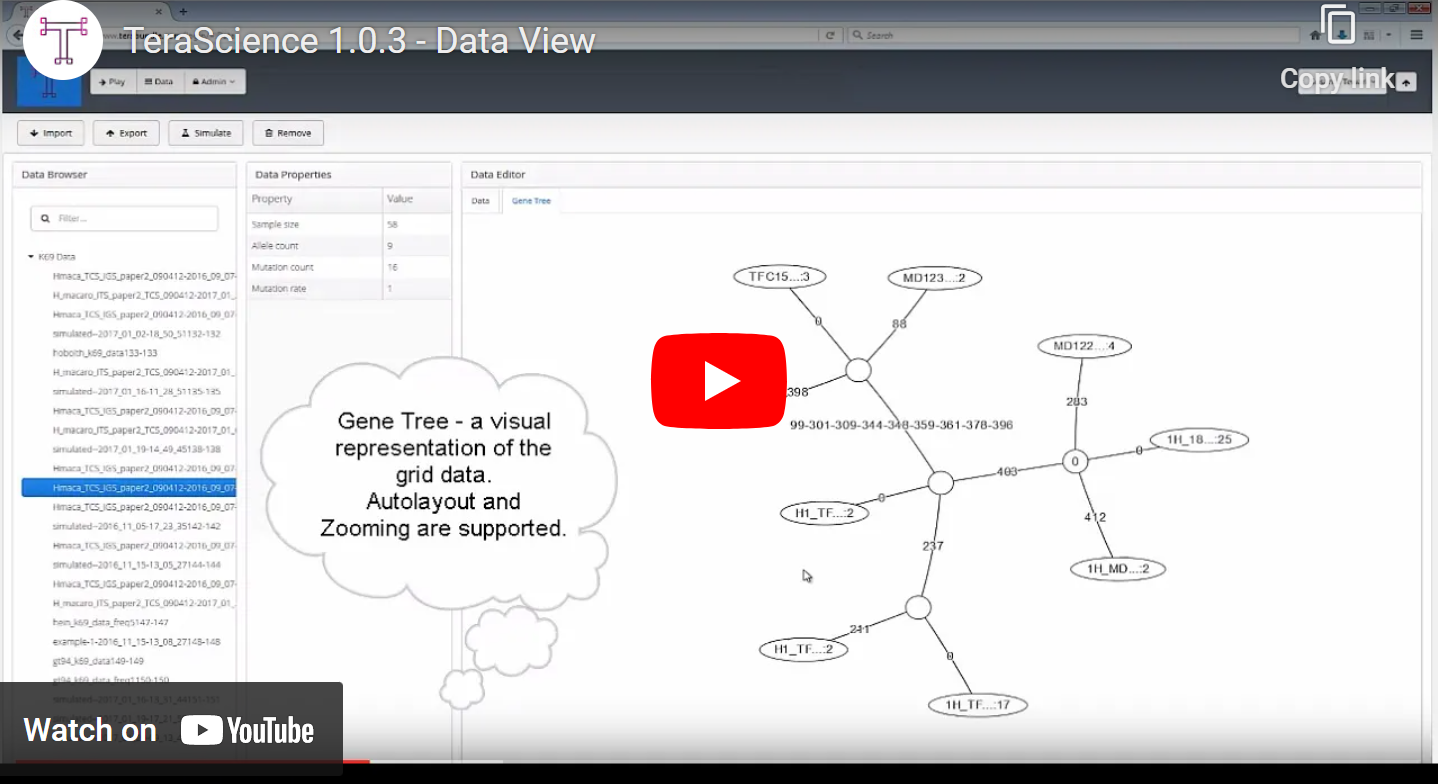
Reusable Data Visualization, Detached Runtime, and Customized web-based Workflows.
Output processors provide rich data visualizations that are cleanly separated, so that processing logic is reused across console, desktop, and the web. Schedule multiple analysis or repeat a single analysis many times with different input quickly. Execution can be serial, multi-threaded or distributed over LAN or cloud. Easily swap among the runtimes or write your custom runtime. Framework for implementing your unique workflows via user-friendly customizable wizards automating data cleaning and pre-processing steps. Data browsers, editors and advanced visualizations allow quick exploration, giving users a first-class ride.